How we built docs.moov.io
It’s been said by many that “docs are the product” and that “docs are the most important part of the product.” We couldn’t agree more. What good is our product if developers don’t know how to use it? And do developers tend to read the docs, or do they search and skim? We know, because we’ve been in that position ourselves.
At Moov, we knew from the beginning that our documentation needed to be as good as our product, with just as much care and concern. In fact, the majority of our user-testing in the early days of our product was centered around our docs site.
These are the technology choices that we made to create our docs. These same choices and tradeoffs may not be right for you. In this article, learn how we use static site generators, serverless functions, and source control to build and deploy our developer documentation at Moov.
Knowing our users
Our readers typically fit into one of these camps:
Highly technical - probably a software engineer. Their mission in reading our docs is to figure out how to get started and find terse answers to their obvious next questions. What’s a required field? What are the possible enumerations? What are the error responses I should expect? They may or may not also be subject matter experts in other payment platforms.
Knowledgeable in payments - may be a product manager or a payments operator. These readers know how other payment platforms work and are trying to find patterns that match their understanding.
Knowing this, and knowing that Moov is a little different than other payment processors out there, we’ve modeled our content strategy to prioritize the following:
- Core concepts - Moov has taken a novel approach to simplifying the complexities of moving money, so we start by offering a very brief introduction to the core concepts for which all else is built.
- Quick start - developers want to know how to get up and running without having to talk to anyone. They love copy paste, starting a little sloppy until they figure things out, and refactoring to optimize once they feel more confident in their understanding and approach production-readiness.
- Use case-specific guides - our customers have a mental model of what they’re trying to do, like enabling their customers to accept card payments, or funding their own account so that they can pay out independent contractors. We write these guides to let developers zoom in on the parts of Moov that they need, and forget about the rest.
- API reference - critical to any developer, the API reference is the source of truth for how to craft API requests and the structure of responses. We find return visitors making a bee-line for the API reference, finding their answer quickly, and bouncing.
How we build docs
Our docs site is a statically generated site. We built it on top of Hugo because we love Golang and open source. Hugo is highly customizable, has incredible build times, and produces static assets that can be easily cached for fast browsing.
We developed a “theme” in Hugo-speak. A theme is a package of our own HTML, CSS, JavaScript, and other assets, broken down into reusable components that our different pages can use. We specify layouts, and pages know which layout they’ll use by their type.
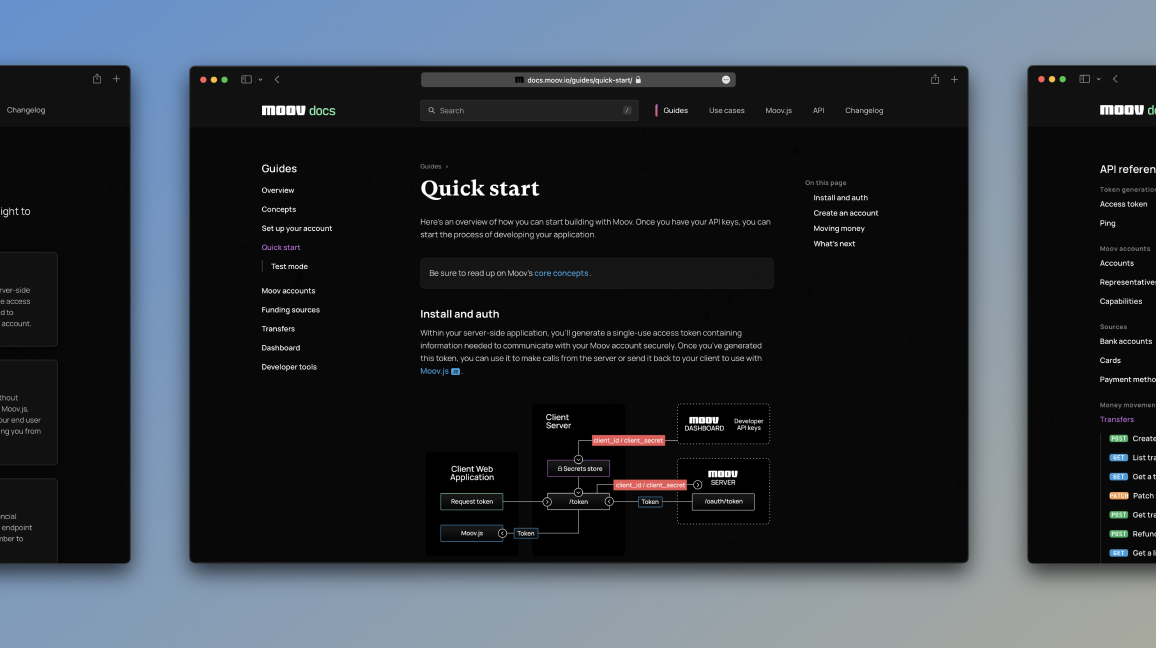
All of our articles are written in Markdown. We use Markdown for our long form content (like this blog post) because we can easily format against a style guide, ensure that we’re following HTML semantics, and it welcomes anyone in the company to contribute.
Hugo’s shortcodes are Markdown’s hidden superpower. We developed our own shortcodes, which are little code snippets we add within Markdown files to do something beyond what Markdown natively supports – like styling notes and notices within a guide, or adding syntax highlighting with tabs for changing the programming language.
The API reference
docs.moov.io/api is part of the same site, but isn’t Markdown content. We embedded Redoc.js to take our OpenAPI specification in YAML format and present it. We theme the heck out of Redoc.js to get it to match the style of the rest of the docs site, and it’s nestled into the same header and footer partials we use in every other page. In Hugo, we created a bespoke page layout that includes the code necessary to embed Redoc, and allows the OpenAPI YAML file to be read and ingested.
If we had one wish, it would be for this page to be statically rendered instead of relying on browser-side JavaScript, but overall we’re happy with the result and our readers are, too.
Searching the docs
When you use the search function on any page of our docs site, the site wakes up a serverless function. This serverless function accepts the search query and searches over the title and content of all of our sites pages that were imported into the function in JSON format.
Why not use Algolia or something else?
We wanted more control over the experience and the quality of the results.
We use elasticlunr in our serverless function for performant searches across a lot of text without the cost. The hardest part of this process was setting up a build process for Hugo to generate all of the content, render it in a single JSON file, and copy that file into a location where the serverless function could read it.
const results = index.search(event.queryStringParameters.s, searchOptions).map((result) => {
const response = searchData[result.ref];
return response;
});
return callback(null, {
statusCode: 200,
body: JSON.stringify(results.slice(0, 10))
});
The searchable JSON file includes not only the content generated from Markdown, but the API reference as well. In our builds, we read in the OpenAPI YAML file that includes all of our API reference material and iterate through each tag and add to the searchable JSON file. Having all content, regardless of how it’s authored, searchable from a single source of truth is what made it possible to build a fast, accurate, and flexible search engine.
Building and deploying
All of our Markdown content is under source control in Github. When we write something, we open a pull request for others to review, and Github Actions deploy a staged version of the site with those changes.
Sometimes we break builds. Syntax errors in shortcodes, or referencing pages that don’t exist will cause a build failure which will be flagged in the pull request.
Once the changes are accepted and builds are green, the pull request is merged which automatically deploys the main branch to the world wide web. Our serverless functions are reloaded and static assets that have changed are re-uploaded with new cache-busting URLs, all done typically in under a minute.
Feedback from you
We hope this overview helps you understand how we build docs at Moov. Making and documenting software is an art form, and we want our users to feel our genuine love for the process. We’re always looking for ways to improve our documentation, so please reach out to us at [email protected] if you have any questions or suggestions. Also, if you want to stay updated on what we’re building, join our monthly newsletter.