


5 ways to improve your asynchronous systems
At Moov, when we design a new system, one of the first conversations we have is what communication methods it will utilize.
Certain communication methods cannot handle large amounts of scaling, while other methods lack the ability to provide quick feedback to the customer. The conversation revolves around the same concepts that Moover Mark Alexander wrote about recently in optimizing communication in distributed systems.
In most cases, our systems use “hybrid communication.” We build a network of HTTP endpoints for synchronous communication, and we partner with Confluent Cloud to provide a Kafka cluster that we utilize for asynchronous processes.
Here are several wonderful references that elaborate on the basics of Kafka:
- This high-level Confluent article discusses the problems that Kafka solves.
- This intro piece from Apache dives a bit more into the mechanics of how Kafka works.
- This Medium post focuses on Kafka’s core concepts.
This blog post isn’t meant to rehash what those industry leaders have already documented. At Moov, we are deep in the trenches of using Kafka for asynchronous communication and have seen the advantages it provides, while also finding different challenges and obstacles to overcome. For software engineers considering Kafka, here are the notable things we have learned while using Kafka in our distributed service platform.
1. Improve reliability with retries
Regardless of which vendor you use for your event management, there is a typical “request, receive, and acknowledge” pattern when pulling events from the queue. Most “event manager” systems build this functionality into their platform so that you, as a consumer, can quickly get events and confirm that the event was received.
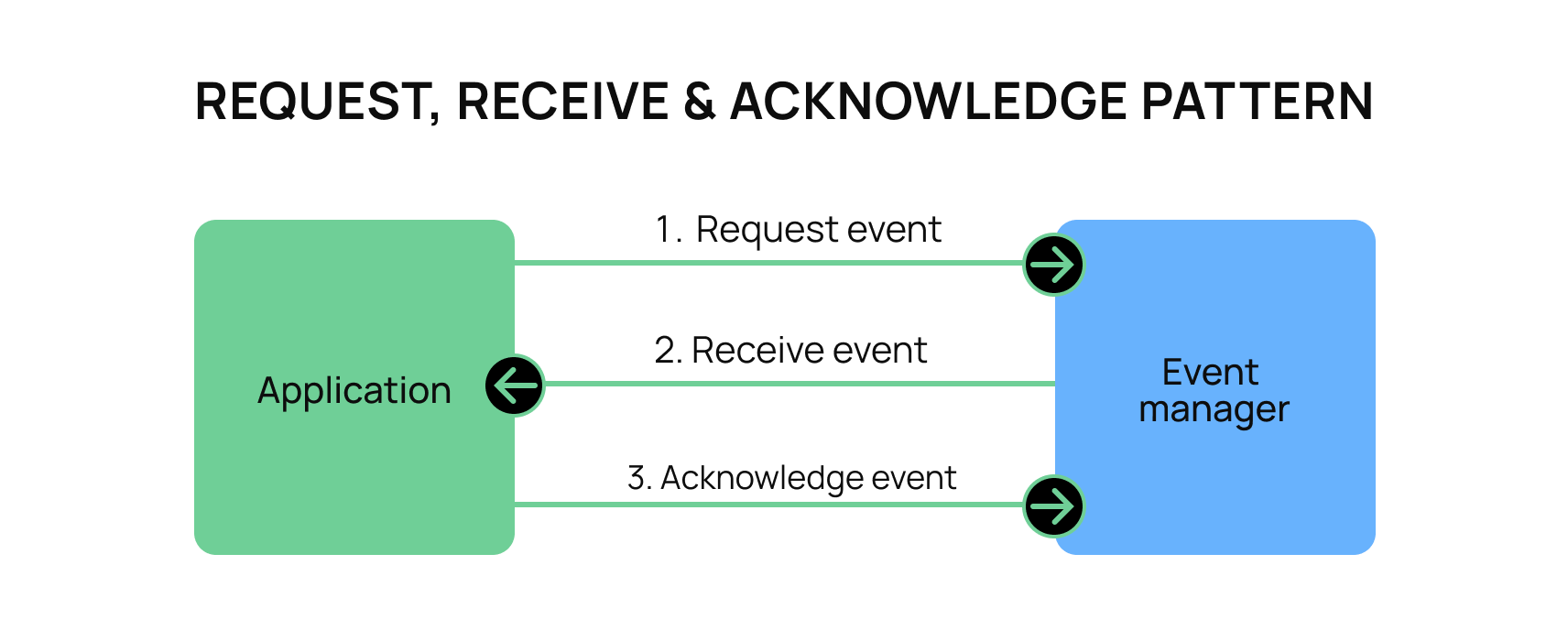
This can take many forms; for example, Kafka uses a “consumer offset” where the consumer indicates where in the queue they are located. AWS Simple Queue Services (SQS) provides the ability for the user to set the acknowledge type for the entire system.
At Moov, we’ve learned firsthand that a wide array of hiccups can occur at any point when processing items from an event queue. Some examples include a database row being locked, an HTTP call to an external service failing, or a race condition for two events from two different topics. As such, we have learned to build in graceful error handling and establish retry loops within our services.
We achieve this by separating event consumption from application actions. We create a thin decision-maker that sits between the application and the event manager. We will refer to this as the “consumer.” The consumer’s total purpose is to retrieve events from the event manager and pass them along to the application.
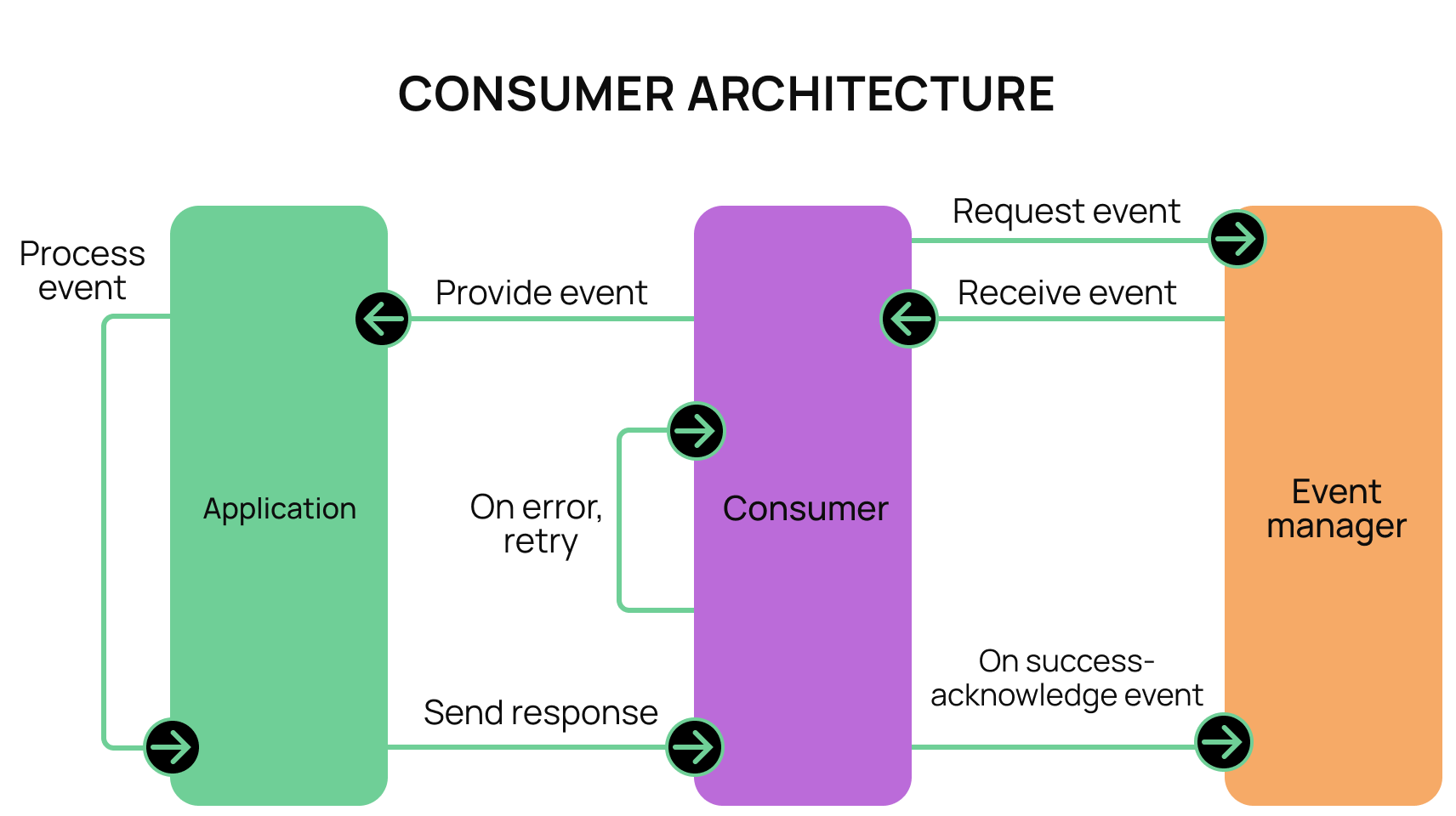
When the application successfully processes an event, it will send the appropriate acknowledgment to the event manager. However, in the case of an error, it will instead resend the failed event back to the application for reprocessing. This improves the reliability and resiliency of the services.
2. Enhance retry logic with flagging
At Moov, our initial draft of our consumer retry logic was quite simple. It had a hard limit for the number of retries it would attempt, and then it would halt once that limit was reached. However, we found through use that there were nuanced cases where an application wanted the retry logic to be an optional process. After many design considerations, we found it empowering to enhance our event consumer processes with error flagging.
Error flagging refers to the process of attaching a piece of metadata to a surfaced error. This metadata is not part of the error message, but it can be added and retrieved from an error. For example, a downstream service can mark an error to indicate that certain data is “invalid,” and the upstream services can retrieve this data and make conditional decisions based on that metadata.

In the case of our consumer processes, we found many scenarios where conditional logic in the consumer “agent” would be beneficial.
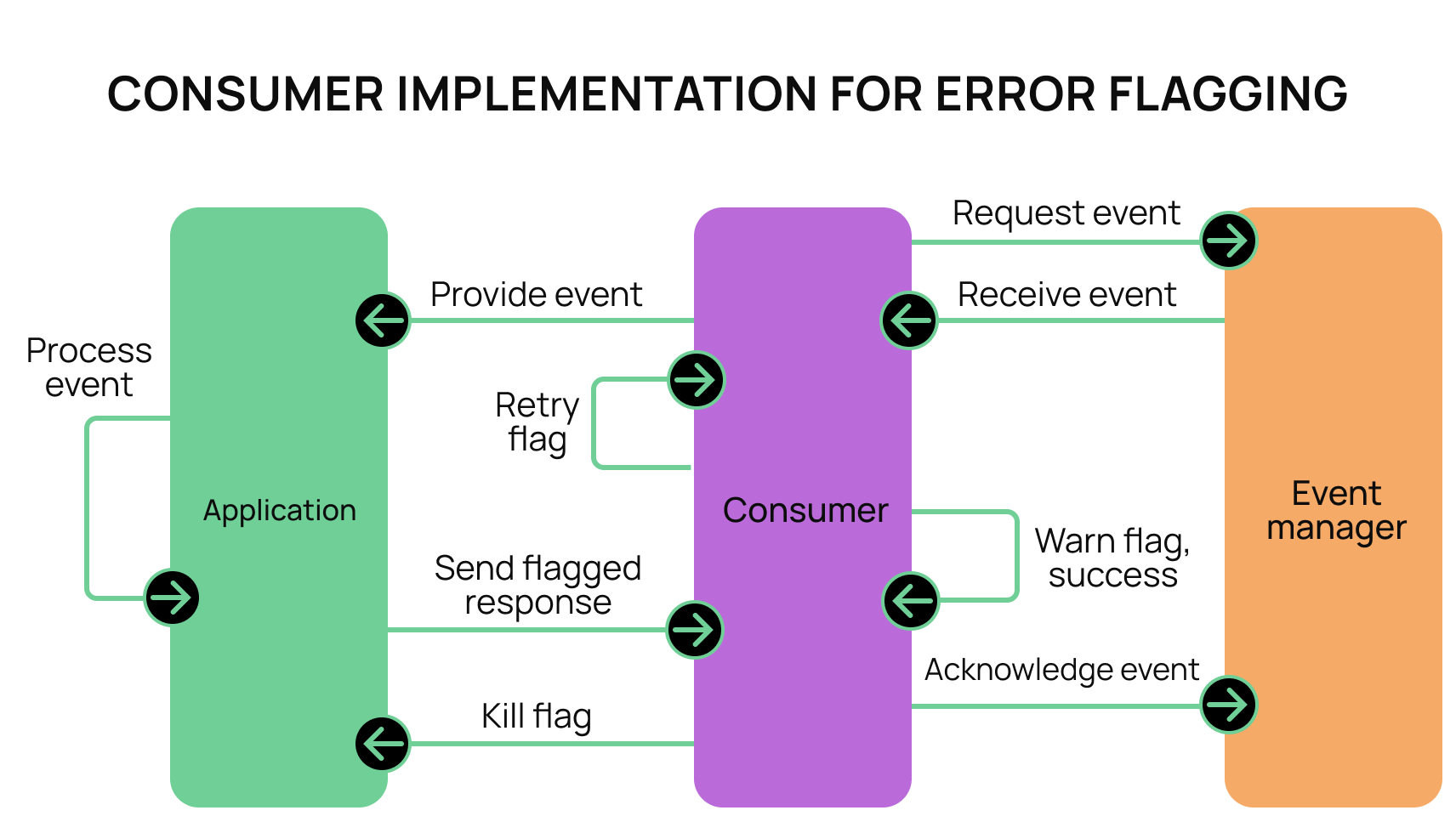
We decided on the following use cases for our flags:
- Success - indicated by a lack of an error. Leads to an acknowledgment.
- Warning error - the application returns an error, but has flagged it to indicate a warning. The error is logged and the consumer continues in the queue.
- Retry error - the application returns an error, but has flagged that it would like to retry the event. The consumer does not advance in the queue and resends the event back to the application. The consumer also keeps track of the number of retries, and will halt the service if the retry attempts exceed a preset amount.
- Kill error - the application returns a flagged error indicating that it has experienced a fatal error. In response, the consumer sends a kill command to the application which will cause it to shut down.
Your particular application may require something more nuanced than what is described above, however, we found this sufficient for our use cases. The main benefit of this enhancement is that it empowers the applications to be in control of how the consumer processes should behave while still allowing for a single consumer “agent” to be in control of communicating with the event queue.
3. Reduce errors through consumer idempotency
A small but important detail of any event consumer system is to ensure that duplicate events become a no-op. How you personally design your system to identify duplicate events is entirely up to the architecture of your system, but identifying duplicates is crucial to having your services run smoothly.
For example, a Kafka cluster can be deployed in the “at least once” consumption strategy to ensure that all events are received. The “at least once” configuration for Kafka ensures that an event will be consumed at least once for each consumer, which is great for services that always require those events to be processed. However, this means that if you have two consumers listening to the same consumer group, there is a small chance that two of your consumers will pick up the same event and both attempt to process it.
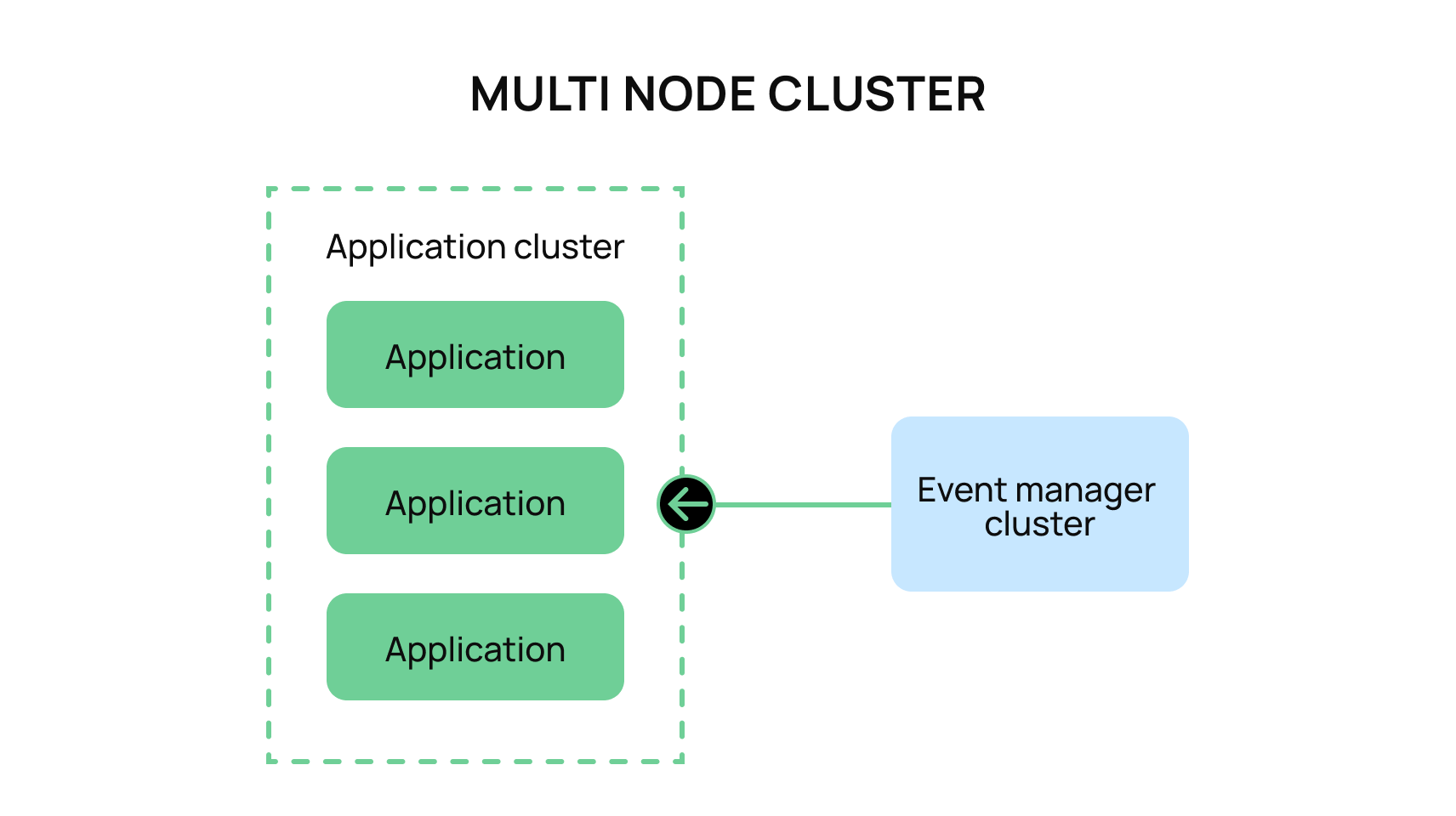
Anytime two different application nodes pick up the same event it can result in an error as both events race to update the same data. We recommend that you write the service logic for your event consumers to always be idempotent. However, an alternative solution is to build in a state machine to indicate that a record is already being updated or processed that can act as a source of truth for items in flight.
4. Create supportability by replaying events
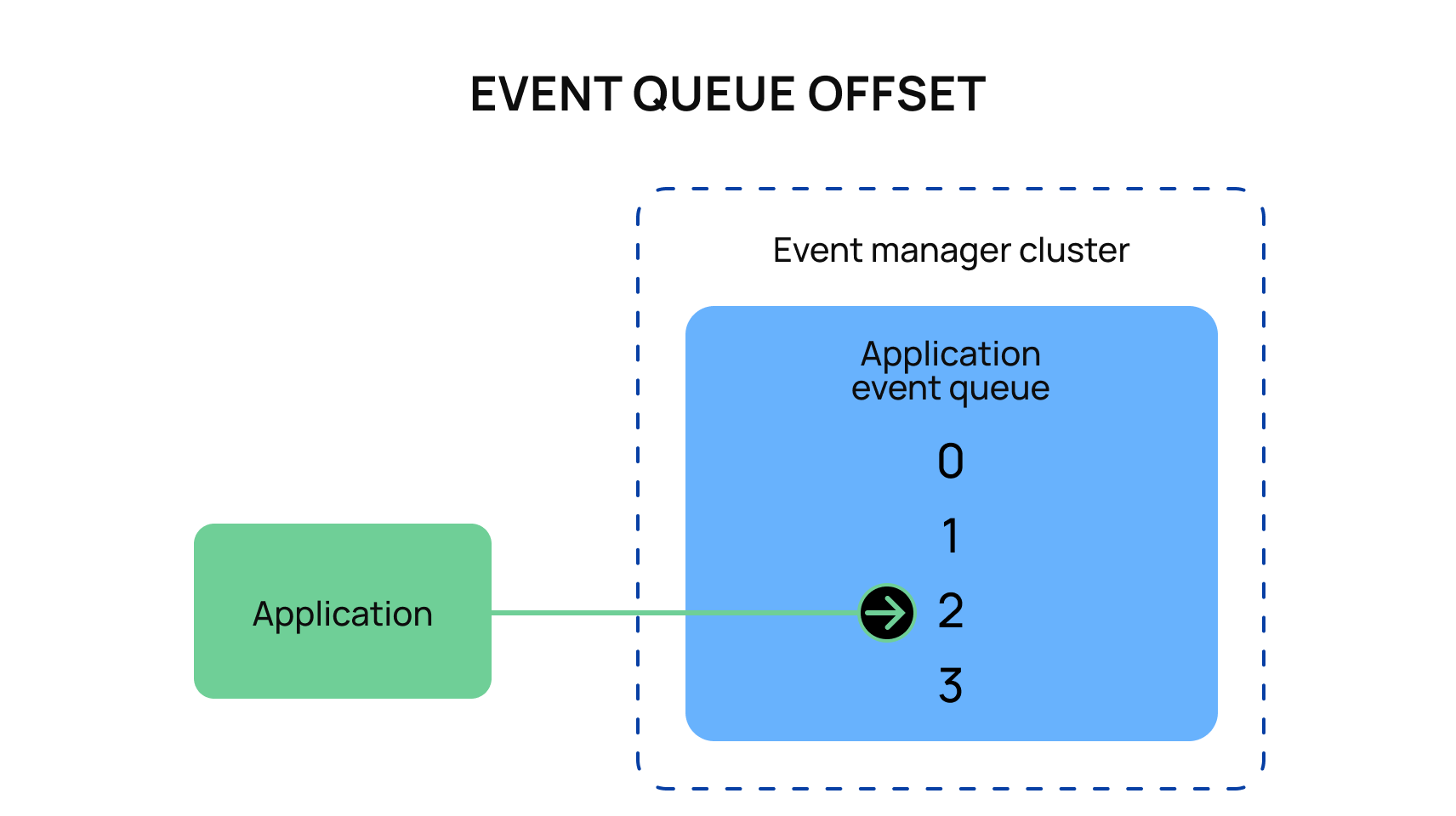
Kafka has the ability to allow each consumer to set an offset, which is how far they have processed through the series of events that Kafka has produced. Consumers automatically update their personal offset as they process events. However, it is possible for a user to manually intervene and return the consumer offset to an earlier state to allow a consumer to “replay” those events.
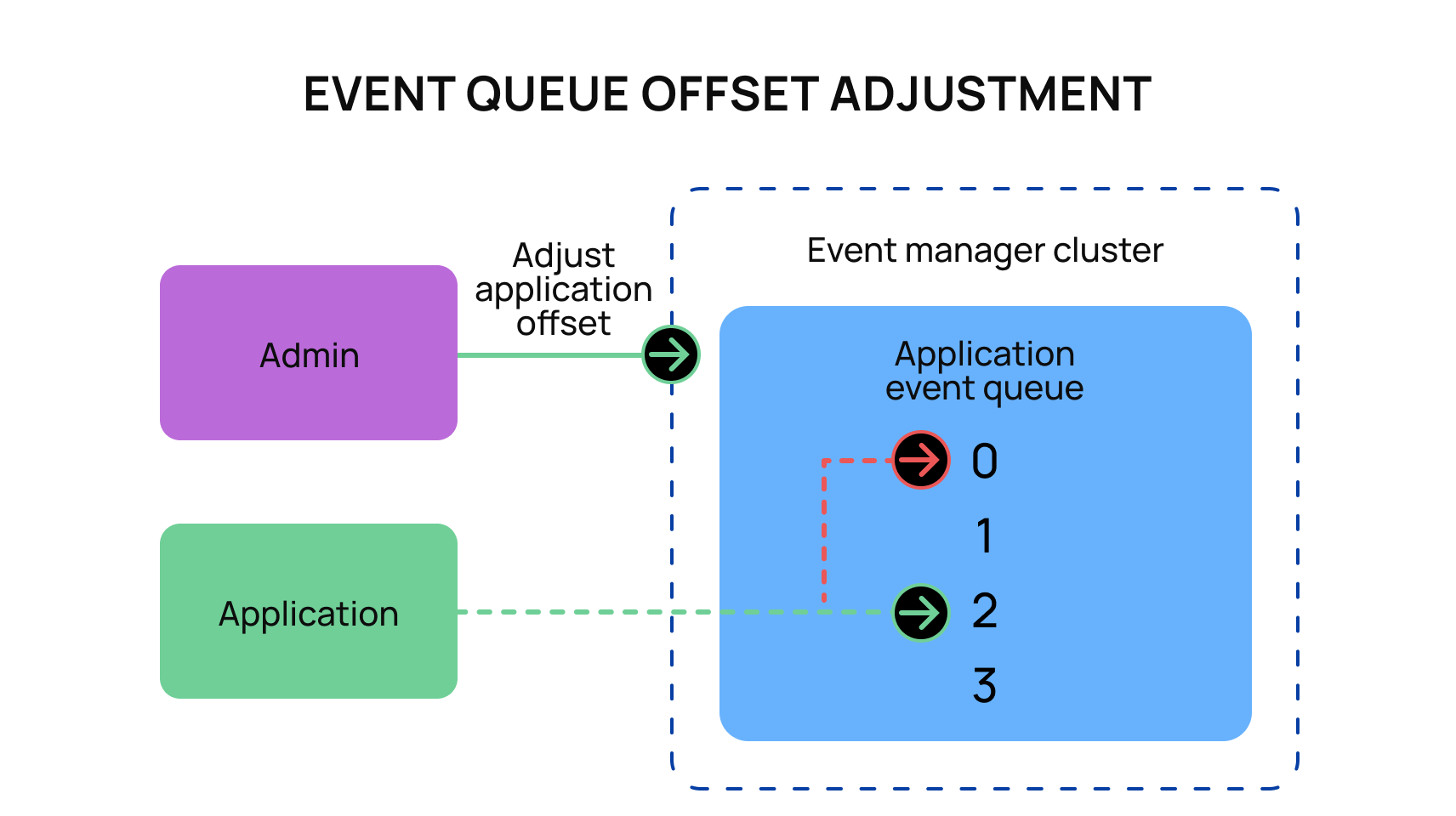
This is a wonderful feature that is essential for all interactions with Kafka. There are many scenarios where poor behavior can harm the consumption process. For example, your application had an unexpected bug, two events from two different topics may be consumed out of order, your application has been updated with new expectations, etc.
Being able to replay those events creates a safety net that allows for quick and easy triage of all parts of the consuming process. Ideally, you never have to replay those events and never have to touch anything related to it, but the moment you need it, replayability becomes an essential tool to assist your processes.
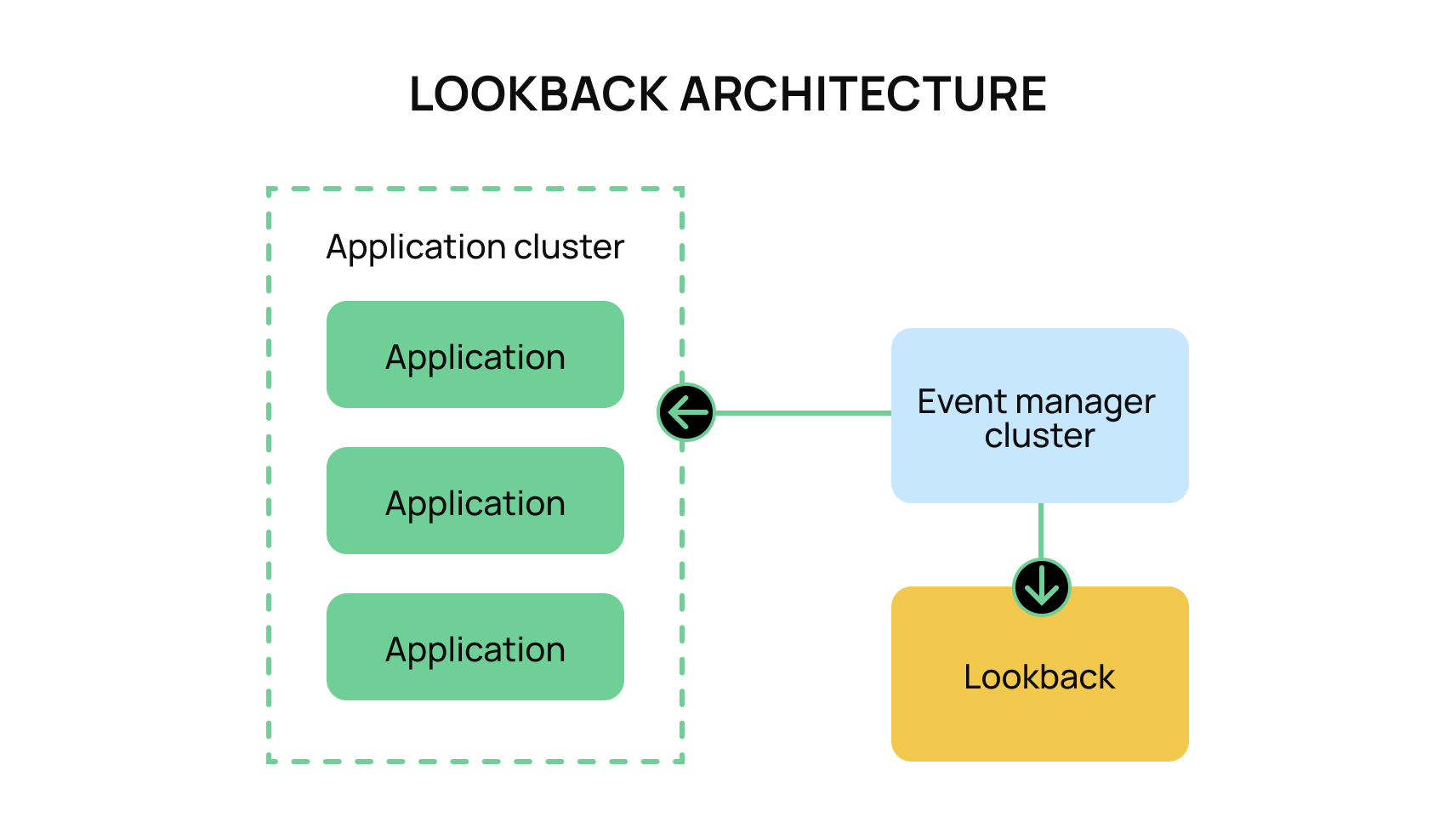
Moov firmly believes in the ability to replay events when needed, and we have established an independent service we label “lookback.” This service listens to all events that occur across our platform, and it stores them for independent auditing and “replay-ability.” This allows our platform to have even more fine-grained control of replayable events as compared to leveraging traditional offsets.
5. Improve maintainability by only storing what you need
When processing event data in an external service, it is incredibly tempting to store “as much data as possible.” The “just in case” mentality can cause many developers to fall into over-optimization and caching too much data.
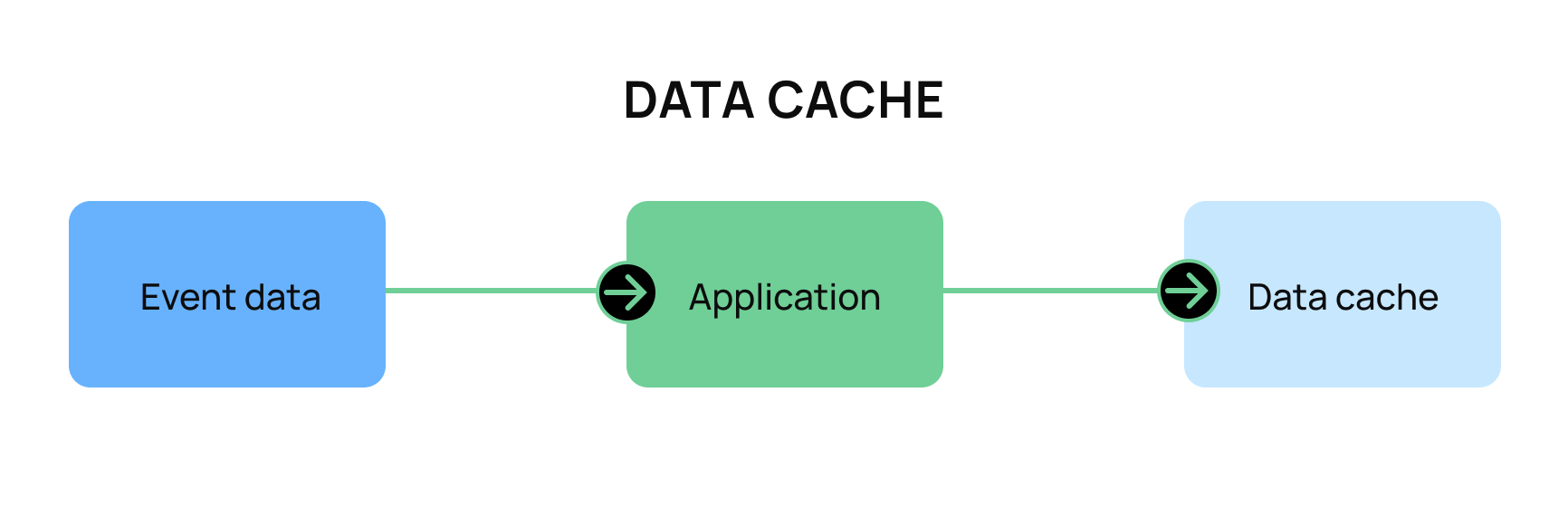
However, data stored in cache creates a “data debt.” While it can be tempting to store all of the data for whatever processes (reports, business decisions, etc), it’s always worth asking, “Am I prepared to take on the debt that this cache requires?” In this case, “data debt’’ refers to the required processes in place to ensure that the cached data is accurate (stored correctly) and up to date (reflects the current state in other parts of the system). At Moov, we only keep the minimal amount of data possible and rely on the application that produced the event for any data beyond that point.
To illustrate an example of this, let’s look at the needs of a potential reporting service that is designed to pull in data from multiple parts of the system. This reporting service needs to be built to support upwards of millions of records. It also needs to be built in a way that it reads events as fast as possible. It lastly needs to store data from Events A, B, and C.
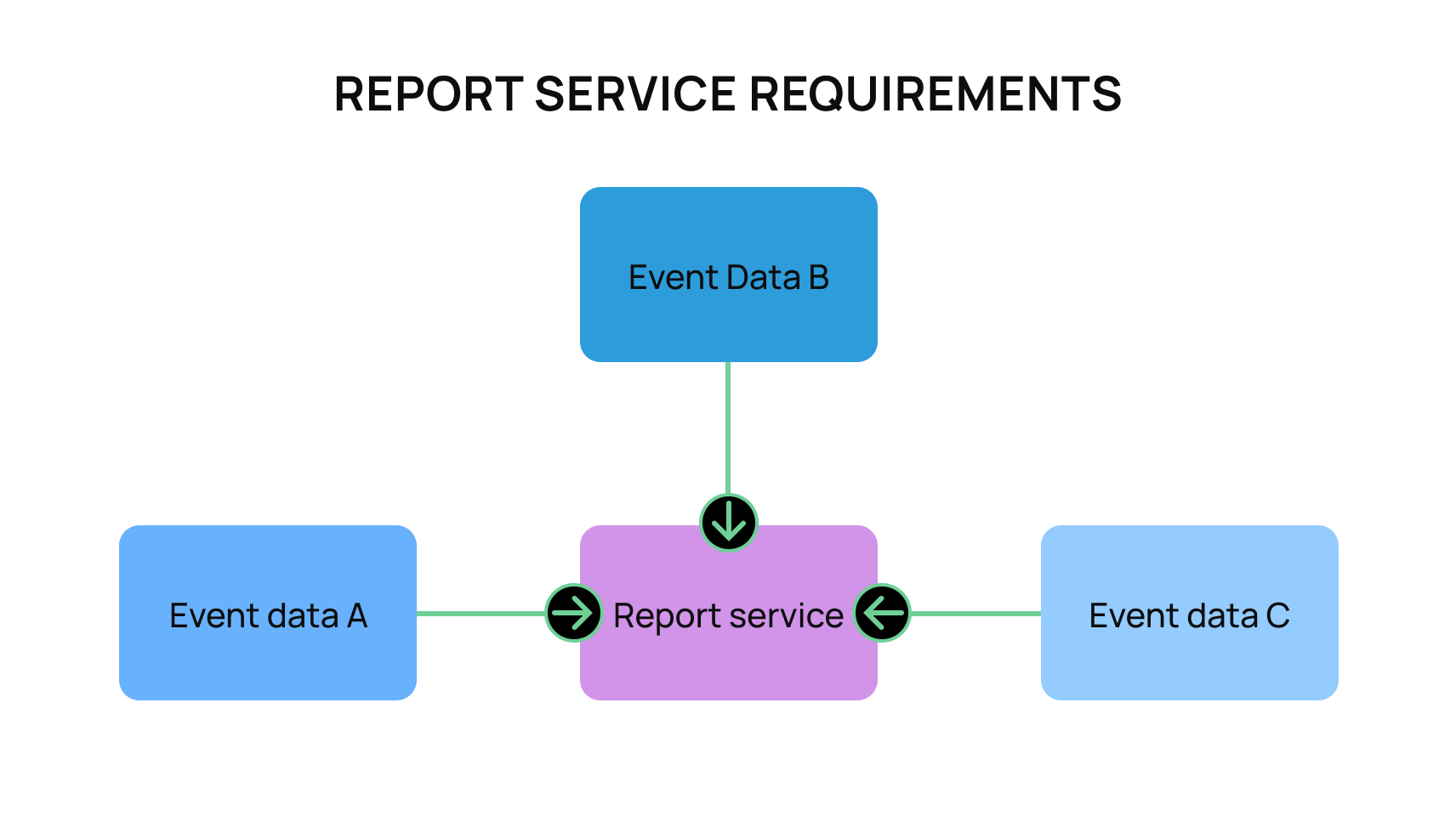
For the sake of this example, let’s say that the product definitions for this report are very clear for Events A and B. On top of that, Events A and B are immutable and extremely minimal. So they will never be updated and are quite small. However, it’s unclear what is mission-critical for Event C. Also, the data from Event C is quite large and would take a significant time to map out all of the data it stores. Currently, the Product Team is only aware of a handful of needed fields, but wants the ability to add more as needed. It’s also assumed for this project that the team’s ability to dedicate time is quite limited, so the team needs to build the best solution possible as quickly as possible.
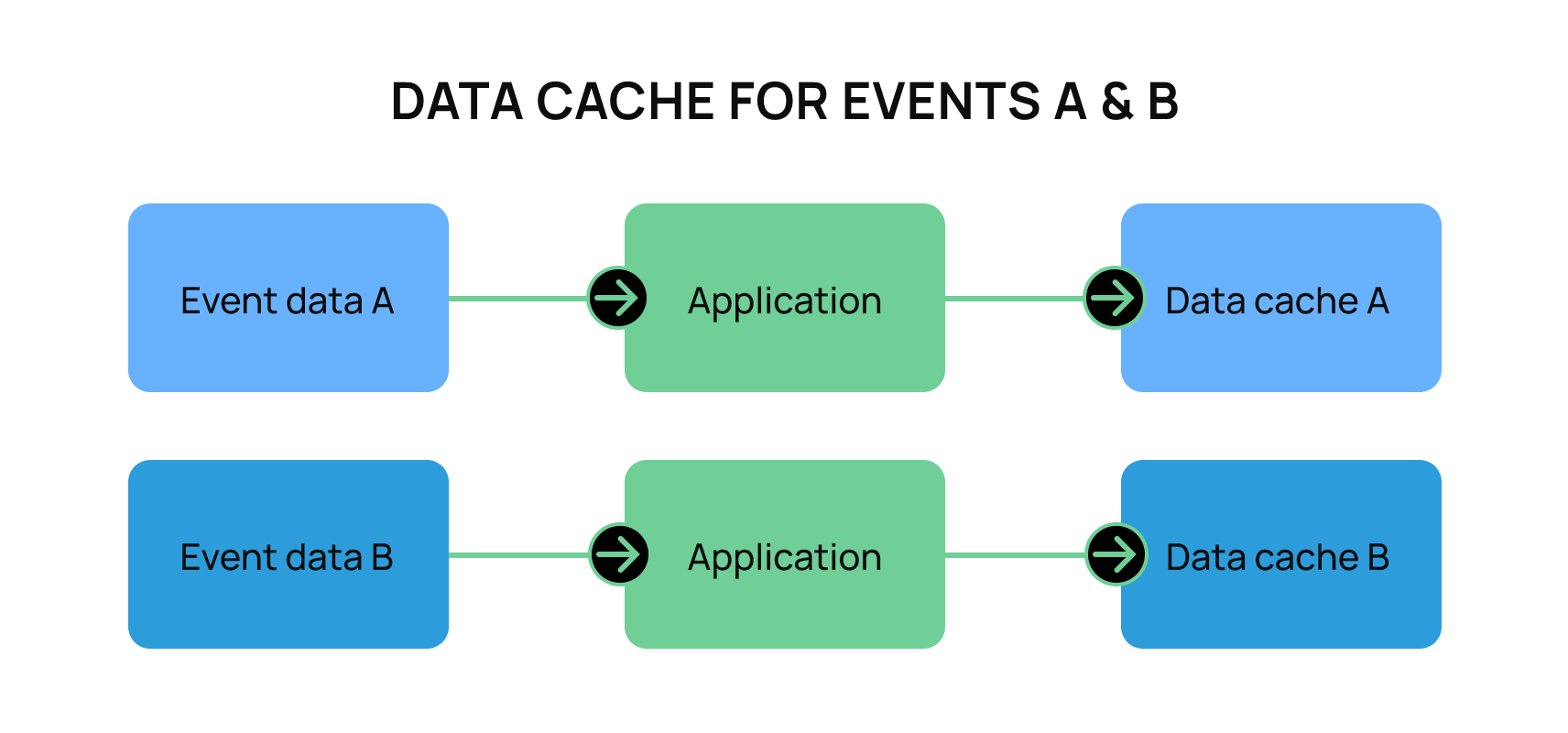
In this case, because the report service needs to have the ability to quickly process as many records as possible, it will likely need to store a significant amount of that data. Events A and B are likely good candidates for a “data debt.” The needed data from the events are minimal and are never updated.
However, Event C is a more difficult problem to solve. Does the engineering team try to store the entire object in a relational format and pay the debt of maintaining that large object? Or does the team choose the minimal amount of fields to store, knowing that it will require more work down the line to add in more data when needed in the report? For the sake of this example, let’s assume there is an extremely clever engineer who decides to avoid both options. As the data does not need to be indexed and can simply be retrieved for the report data, it would be possible to break the concept of the first normal form and store the entire contents of Event Data C as some level of marshaled data (JSON, byte array, etc).
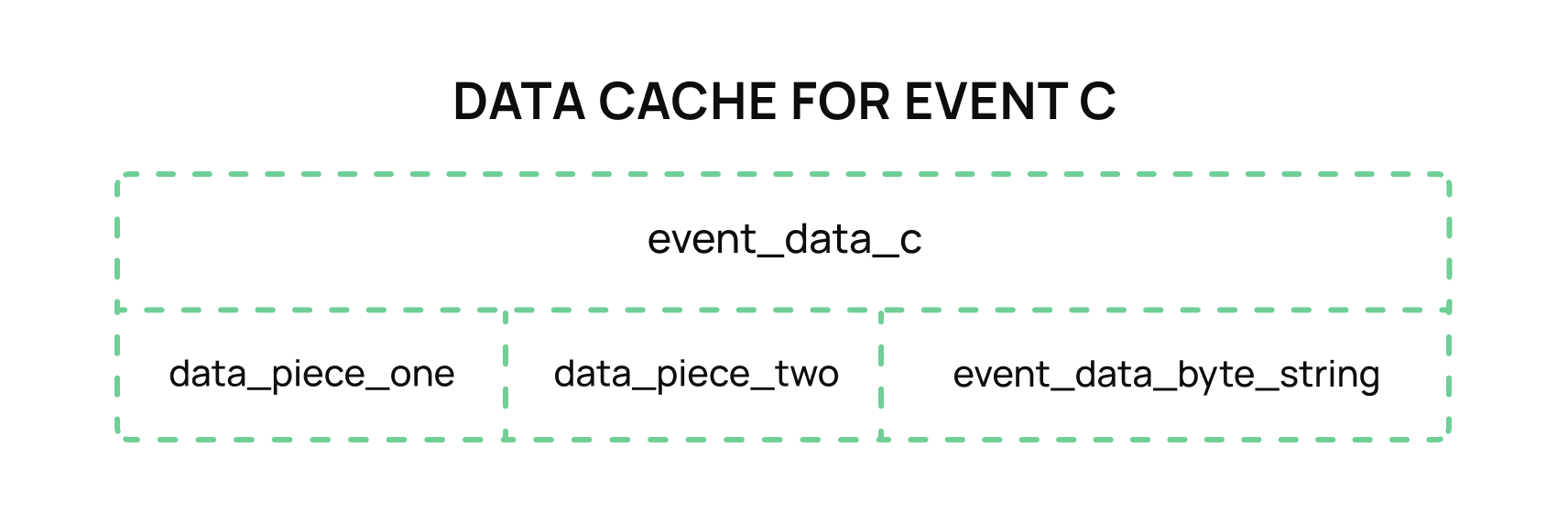
This solution provides for 1-2 columns needed for searching, but otherwise, the rest of the data is stored as a snapshot of the event as it was received. The service in this case can easily marshal/unmarshal the contents of the cached data, and it can pick and choose the data needed as the application grows. The engineer implements this solution, marvels at how easy it was to implement this logic and pats themself on the back for a job well done.
If this quick solution has ever been implemented in your system, you’re likely aware of the current problems that are quick to fall upon this example team.
There are a myriad of problems here that can almost immediately occur, such as:
- Inability to use “cheap” lookup operators
- Can’t use the following operators:
- =, <, >
- IN
- NOT
- Must use the following processes:
- Regex
- %LIKE% operators
- Comparing byte arrays for differences
- Can’t use the following operators:
- Inability to support backward compatibility
- Fields removed from the data model
- Fields renamed on the data model
- Inability to support forwards compatibility
- New fields are not present
- Migrations to add new fields require
- string manipulation
- byte manipulation
- extracting the entire data field, transforming it into an object, manipulating it, and then transforming it back to the data field
This list can continue. The moral of the story is, while maintaining a data cache is difficult, maintaining a snapshot of an object in your data cache is even more difficult in a traditional relational database. When picking what “data debt” you want to take on for your team, be sure it is:
- Relevant to your current needs
- Able to be maintained in sync with the rest of the system
- Supports both backwards and forwards compatibility
Summary
An event manager can transform a system from a good system to a great system. The ability to handle load in parallel and in an asynchronous manner can radically transform a platform’s ability to scale.
In our effort to both respect the craft of software engineering and give first to others, we hope that these five points will help empower your team’s ability to take your product to the next level.
We also hope you’ll share your experiences building your fintech projects with our community of builders.


